本文共 2681 字,大约阅读时间需要 8 分钟。
本次直播由CMU计算机学院副教授马坚、斯坦福AI博士生、李飞飞教授的学生Jim Fan、杜克大学温伟为大家带来NIPS 2017全程直播。特别感谢Jim 提供照片。
参会人数从100激增到8500,不变的是创造智能的梦
三十一年,一代科学巨匠们的辉煌历史!主席说,他当年在Denver参加第一届NIPS的时候只有一百多人,而今年有超过8500人注册。人数在逐年指数增长,而唯一不变的是那古老的创造智能的梦。
这次大会共有2个并行的track,都分别包括oral和spotlight。新增了艺术创作大赛(其中GAN的发展起了很大的推动作用),还有一个舞会(在学术会议举办舞会,也确实算创新)。

大会程序主席Samy Bengio致辞
3240篇提交论文,覆盖156个子领域,算法最受关注,深度学习其次
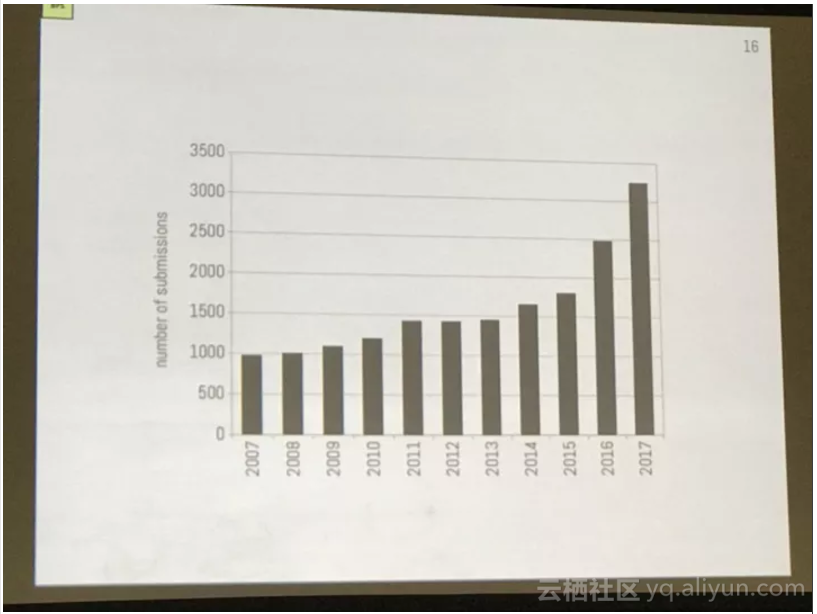
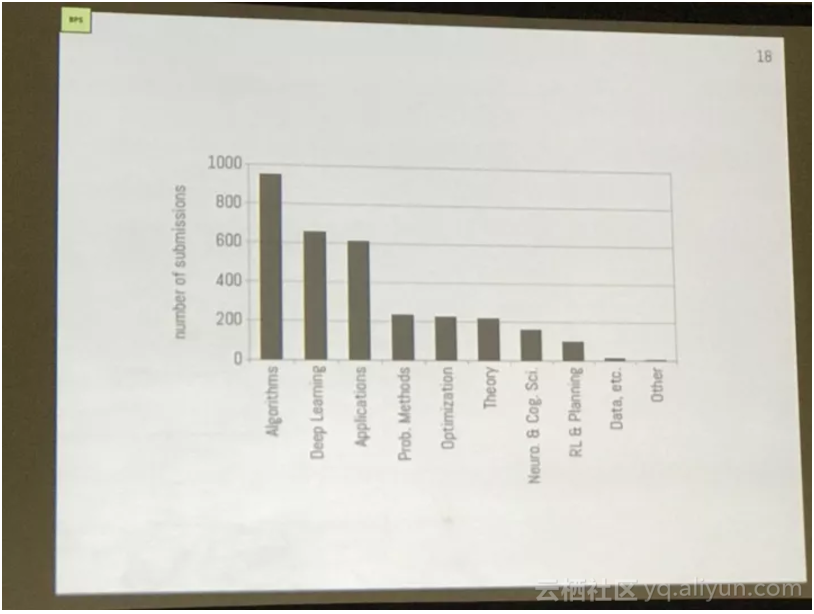
本届大会一共收到3240篇论文(相较去年有明显增多),覆盖156个子领域(相比去年增长了150%),最受关注的是算法,其次是深度学习,紧跟其后的是应用。
之后依次是:问题方法、优化、理论、神经和认知科学、数据、其他。
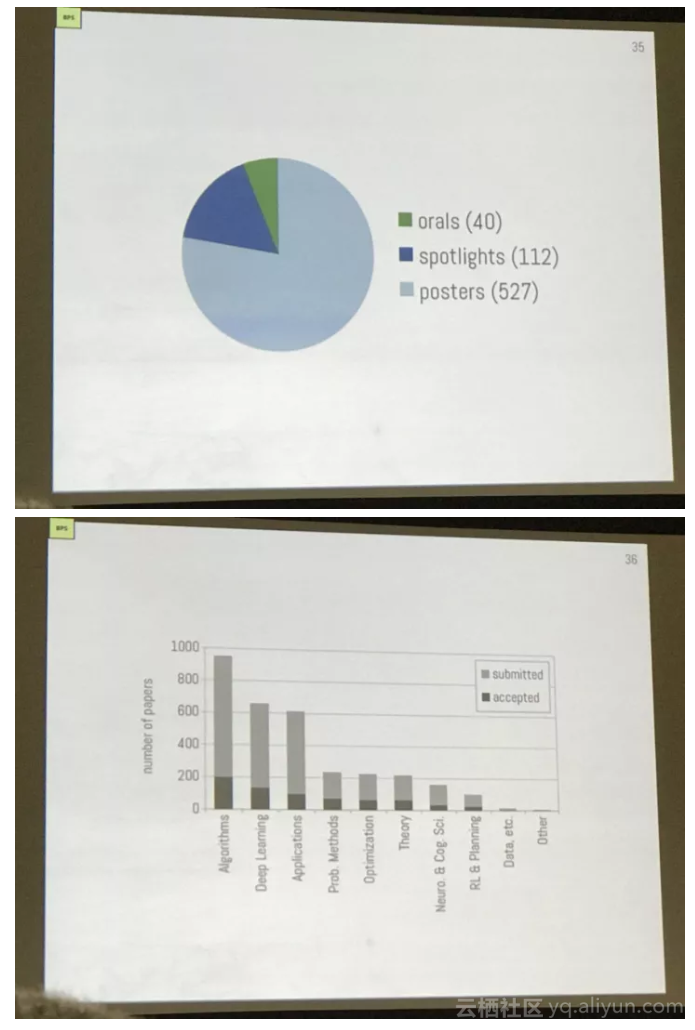
接收论文共2093篇,录取率为21%,稍稍高于去年,其中40篇Oral,spotlight 112篇,poster 527篇,这些论文的领域分布如下:
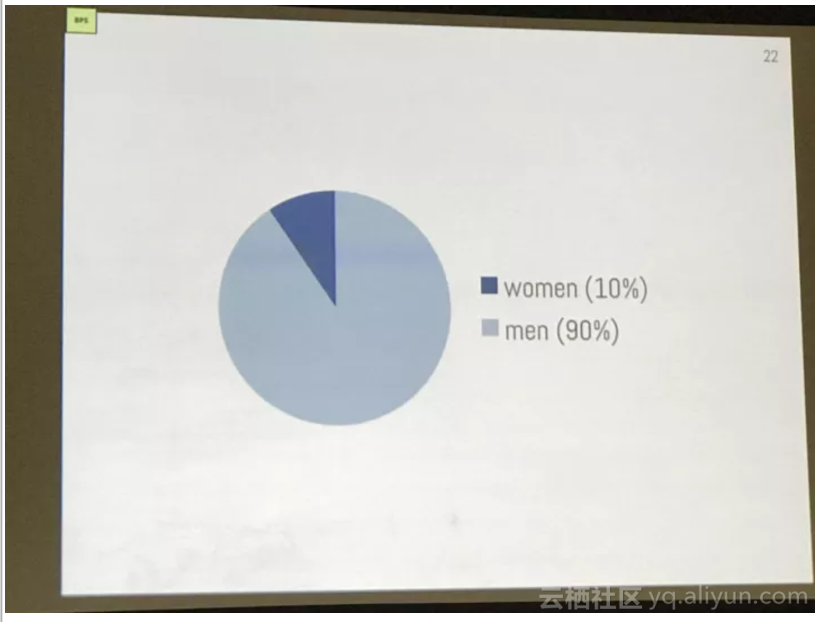
10000个作者,90%是男性
那么,这些论文都出自谁的手?

统计表明,如果只看论文署名,有1万个作者(authorship),平均每篇论文3.4个作者。除去以为作者参与多篇论文的情况后,单独看,共有7844位不同的作者。
![]()

7844人!
其中,绝大部分是男性(90%)。
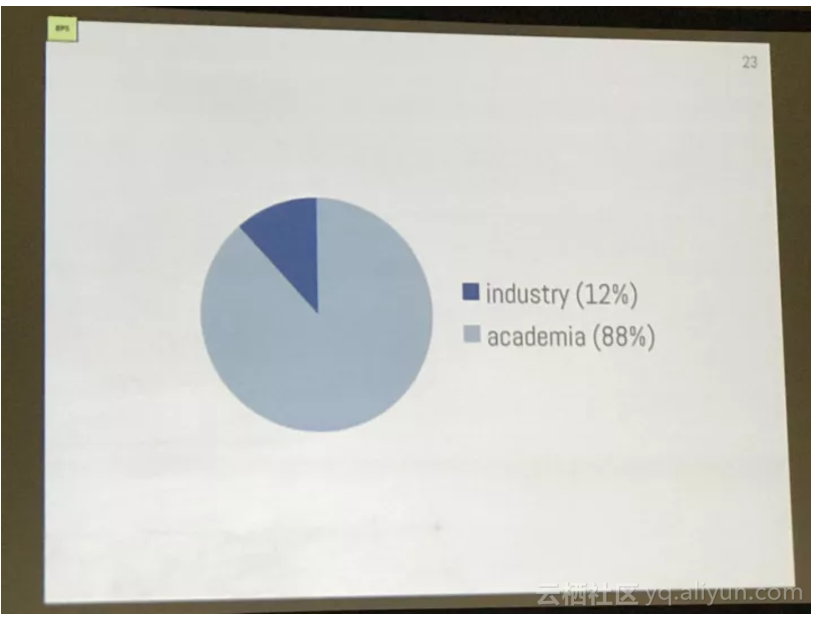
组委会从中抽取了10%的论文做调查,发现学术界和工业界提交论文的比例是12:88。
200+领域主席,2093位专家评审,9747条评审意见
有将近8000位作者写论文,会务组也辛苦找到了2093位评审,而且是专家评审,实在不易。
183位领域主席(相比去年增长了83%),由于领域主席实在太多,本届大会还新增了“资深领域主席”,一共26位。大会组委会引入了下面的论文评审规则,包括保持每位评审不超过6篇论文,领域主席不超过18篇论文,而资深领域主席最多只能负责8个领域。

他们一共给出了9747条评审意见(每篇论文至少有3条意见):

3篇最佳论文及1篇经典论文

今年NIPS共评选出3篇最佳论文,而经典论文奖授予了10年前一篇与随机特征搜索相关的论文。下面做简单介绍:
一、最佳论文奖(3篇)
1、Safe and Nested Subgame Solving for Imperfect-Information Games

摘要:在不完全信息博弈中,子博弈(subgame)中的最优策略可能取决于其他尚未完成的(unreached)子博弈中的策略。因此,单个子博弈不能孤立地解决,而必须考虑整个游戏的策略,这一点与完全信息游戏十分不同。但是,也可以首先逼近整个博弈的解决方案,然后通过解决个别子博弈来改进它。这被称为子博弈解决(subgame solving)。我们提出了在理论和实践中均超越以前方法的子博弈解决技术。我们还展示了如何调整它们以及过去的子博弈解决技术,以应对原始行动抽象之外的对手行为;得到的结果显著优于先前的state-of-the-art方法,动作翻译(action translation)。最后,我们表明子博弈解决可以随着博弈树不断重复,使得exploitability大幅降低。这些技术是Libratus的一个关键组成部分,Libratus是第一个在单挑无限手德州扑克中击败顶级人类玩家的AI。
2、Variance-based Regularization with Convex Objectives

摘要:我们开发了一种风险最小化和随机优化的方法,该方法为方差提供了的凸属性代替项,允许逼近和估计误差之间的近似最优和计算有效的平衡。 我们的方法建立在分布鲁棒性优化和欧文经验性似然度的技术基础之上,我们提供了一些有限样本和渐近结果来表示估计器的理论性能。 具体来说,我们证明了我们的过程具有最优证明,并且通过最优化的近似和估计误差,在更一般的设置下实现更快的收敛速度而不是经验风险最小化。 我们给出确凿的经验证据,表明在实践中,估计器实际上在训练样本上的方差和绝对性能之间进行交换,对于许多分类问题,超出标准经验风险最小化的样本外(测试)性能。论文地址:https://arxiv.org/pdf/1610.02581
3、A Linear-Time Kernel Goodness-of-Fit Test

摘要:我们提出了一种新的goodness-of-fit的自适应测试,其样本数量的计算成本是线性的。我们通过最小化假阴性率来了解最能显示观察样本与参考模型之间差异的测试特征。这些特征是通过Stein的方法构造的,这意味着没有必要计算模型的归一化常数。我们分析了新测试的渐近Bahadur效率,证明了在一个均值偏移的情况下,无论选择哪个测试参数,我们的测试总是比先前的线性时间内核测试具有更高的相对效率。在实验中,我们的方法的性能超过了早期的线性时间测试,与二次时间内核测试(quadratic-time kernel test)的功效相当甚至更好。在高维和可以利用模型结构的情况下,我们的拟合优度比基于最大平均偏差(Maximum Mean Discrepancy)的二次时间二样本测试性能得好得多。论文地址:https://arxiv.org/abs/1705.07673
二、经典论文奖:
“经典论文奖”被授予了2007年在NIPS发表的《大规模内核机器随机特征搜索》,目前已经被引用1000多次。

摘要:为了加速对内核机器的训练,我们提出将输入数据映射到随机化的低维特征空间,然后应用现有的快速线性方法。我们设计了随机特征,使变换后的数据内积近似于用户指定的移位不变(shift-invariant)内核特征空间中的内积。我们研究了两组随机特征,提供了它们近似各种径向基核的收敛范围,并表明在大规模分类和回归任务中,使用这些特征的线性机器学习算法的性能,要优于目前最先进的大规模内核机器。地址:https://people.eecs.berkeley.edu/~brecht/papers/07.rah.rec.nips.pdf
原文发布时间为:2017-12-5
本文作者:闻菲
本文来自云栖社区合作伙伴新智元,了解相关信息可以关注“AI_era”微信公众号
原文链接:
转载地址:http://bibsx.baihongyu.com/